library(CDMConnector)
library(dplyr)
library(tidyr)
library(DBI)
db <- DBI::dbConnect(duckdb::duckdb(),
dbdir = CDMConnector::eunomiaDir())
cdm <- cdmFromCon(
con = db,
cdmSchema = "main",
writeSchema = "main"
)CodelistGenerator
CodelistGenerator (and a little omopcept)
Working with the OMOP CDM vocabulary tables


Reference to the CDM vocabulary tables
Reference to the CDM vocabulary tables
cdm── # OMOP CDM reference (duckdb) of Synthea ──────────────────────────────────────────────────────────────────────────────────────• omop tables: person, observation_period, visit_occurrence, visit_detail, condition_occurrence, drug_exposure,
procedure_occurrence, device_exposure, measurement, observation, death, note, note_nlp, specimen, fact_relationship, location,
care_site, provider, payer_plan_period, cost, drug_era, dose_era, condition_era, metadata, cdm_source, concept, vocabulary,
domain, concept_class, concept_relationship, relationship, concept_synonym, concept_ancestor, source_to_concept_map,
drug_strength• cohort tables: -• achilles tables: -• other tables: -Reference to the CDM vocabulary tables
Note, Eunomia doesn´t have a full set of vocabularies:
Reference to the CDM vocabulary tables
# remotes::install_github("SAFEHR-data/omopcept")
library(omopcept)
library(ggplot2)
concept_df <- cdm$concept |> collect()
arrow::write_parquet(concept_df, "concept.parquet")
concept_summary <- omop_concept(location = here::here()) |>
count(vocabulary_id) |>
collect()
concept_summary |>
ggplot()+
geom_col(aes(vocabulary_id, n)) +
theme_minimal() +
xlab("") +
ylab("Concept count")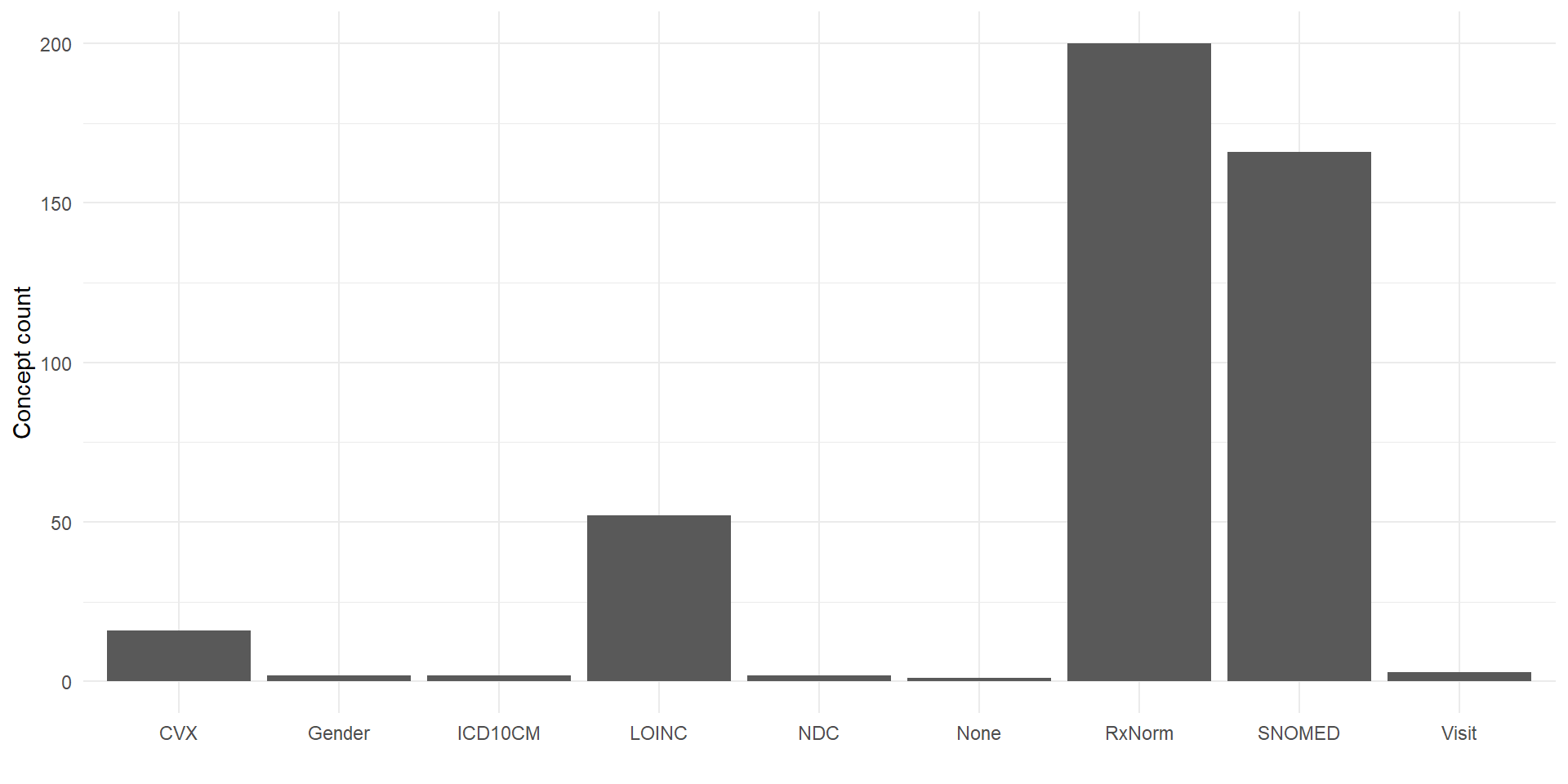
Reference to the CDM vocabulary tables
We’ll create a mock to show some of the functions where Eunomia won’t work because of its partial vocabularies
library(CodelistGenerator)
cdm_mock <- mockVocabRef()
cdm_mockCDM vocabulary tables
CDM vocabulary tables
CDM vocabulary tables
Rows: ??
Columns: 10
Database: DuckDB v1.1.3 [eburn@Windows 10 x64:R 4.4.0/C:\Users\eburn\AppData\Local\Temp\RtmpE1T2Vn\file5a48daf4bd9.duckdb]
$ concept_id <int> 35208414, 1118088, 40213201, 1557272, 4336464, 4295880, 3020630, 19129655, 44923712, 1569708, 40213216,…
$ concept_name <chr> "Gastrointestinal hemorrhage, unspecified", "celecoxib 200 MG Oral Capsule [Celebrex]", "pneumococcal p…
$ domain_id <chr> "Condition", "Drug", "Drug", "Drug", "Procedure", "Procedure", "Measurement", "Drug", "Drug", "Conditio…
$ vocabulary_id <chr> "ICD10CM", "RxNorm", "CVX", "RxNorm", "SNOMED", "SNOMED", "LOINC", "RxNorm", "NDC", "ICD10CM", "CVX", "…
$ concept_class_id <chr> "4-char billing code", "Branded Drug", "CVX", "Ingredient", "Procedure", "Procedure", "Lab Test", "Clin…
$ standard_concept <chr> NA, "S", "S", "S", "S", "S", "S", "S", NA, NA, "S", "S", "S", "S", "S", "S", NA, "S", "S", "S", "S", "S…
$ concept_code <chr> "K92.2", "213469", "33", "46041", "232717009", "76601001", "2885-2", "789980", "00025152531", "K92", "1…
$ valid_start_date <date> 2007-01-01, 1970-01-01, 2008-12-01, 1970-01-01, 1970-01-01, 1970-01-01, 1970-01-01, 2008-03-30, 2000-0…
$ valid_end_date <date> 2099-12-31, 2099-12-31, 2099-12-31, 2099-12-31, 2099-12-31, 2099-12-31, 2099-12-31, 2099-12-31, 2099-1…
$ invalid_reason <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…CDM vocabulary tables
cdm$condition_occurrence %>%
group_by(condition_concept_id) %>%
tally() %>%
left_join(cdm$concept %>%
select("concept_id", "concept_name"),
by = c("condition_concept_id" = "concept_id")) %>%
collect() %>%
arrange(desc(n))# A tibble: 80 × 3
condition_concept_id n concept_name
<int> <dbl> <chr>
1 40481087 17268 Viral sinusitis
2 4112343 10217 Acute viral pharyngitis
3 260139 8184 Acute bronchitis
4 372328 3605 Otitis media
5 80180 2694 Osteoarthritis
6 28060 2656 Streptococcal sore throat
7 81151 1915 Sprain of ankle
8 378001 1013 Concussion with no loss of consciousness
9 4283893 1001 Sinusitis
10 4294548 939 Acute bacterial sinusitis
# ℹ 70 more rowsCDM vocabulary tables
Rows: ??
Columns: 4
Database: DuckDB v1.1.3 [eburn@Windows 10 x64:R 4.4.0/C:\Users\eburn\AppData\Local\Temp\RtmpE1T2Vn\file5a48daf4bd9.duckdb]
$ ancestor_concept_id <int> 4180628, 4179141, 21500574, 21505770, 21503967, 36203060, 36151386, 21502552, 40765628, 4433964…
$ descendant_concept_id <int> 313217, 4146173, 1118084, 1119510, 40162522, 40479422, 1119510, 1112807, 40769189, 19128009, 15…
$ min_levels_of_separation <int> 5, 2, 4, 0, 5, 4, 0, 4, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 2, 2, 0, 0, 2, 0, 0, 0, 0, 0, 0,…
$ max_levels_of_separation <int> 6, 2, 4, 0, 6, 4, 0, 4, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 3, 0, 0, 3, 3, 0, 0, 3, 0, 0, 0, 0, 0, 0,…CDM vocabulary tables
Rows: ??
Columns: 6
Database: DuckDB v1.1.3 [eburn@Windows 10 x64:R 4.4.0/C:\Users\eburn\AppData\Local\Temp\RtmpE1T2Vn\file5a48daf4bd9.duckdb]
$ concept_id_1 <int> 192671, 1118088, 1569708, 35208414, 35208414, 40162359, 44923712, 45011828
$ concept_id_2 <int> 35208414, 44923712, 35208414, 192671, 1569708, 45011828, 1118088, 40162359
$ relationship_id <chr> "Mapped from", "Mapped from", "Subsumes", "Maps to", "Is a", "Mapped from", "Maps to", "Maps to"
$ valid_start_date <date> 1970-01-01, 1970-01-01, 2016-03-25, 1970-01-01, 2016-03-25, 2009-08-03, 1970-01-01, 2009-08-03
$ valid_end_date <date> 2099-12-31, 2099-12-31, 2099-12-31, 2099-12-31, 2099-12-31, 2099-12-31, 2099-12-31, 2099-12-31
$ invalid_reason <chr> NA, NA, NA, NA, NA, NA, NA, NACDM vocabulary tables
Rows: ??
Columns: 3
Database: DuckDB v1.1.3 [eburn@Windows 10 x64:R 4.4.0/C:\Users\eburn\AppData\Local\Temp\RtmpE1T2Vn\file5a48daf4bd9.duckdb]
$ concept_id <int> 964261, 1322184, 441267, 1718412, 4336464, 4102123, 4237458, 4280726, 4330583, 3014576, 4242997, 30…
$ concept_synonym_name <chr> "cyanocobalamin 5000 MCG/ML Injectable Solution", "clopidogrel", "Cystic fibrosis (disorder)", "Kyl…
$ language_concept_id <int> 4180186, 4180186, 4180186, 4180186, 4180186, 4180186, 4180186, 4180186, 4180186, 4180186, 4180186, …Exploring vocabulary tables using CodelistGenerator
Vocabulary version
Search results will be specific to the version of the vocabulary being used
getVocabVersion(cdm)[1] "v5.0 18-JAN-19"Available vocabularies
What vocabularies are available?
getVocabularies(cdm = cdm)[1] "CVX" "Gender" "ICD10CM" "LOINC" "NDC" "None" "RxNorm" "SNOMED" "Visit" Available domains
What domains are present?
getDomains(cdm)[1] "Procedure" "Condition" "Observation" "Visit" "Measurement" "Gender" "Drug" Concept classes
What concept classes are present?
getConceptClassId(cdm,
standardConcept = "Standard",
domain = "Drug")[1] "Branded Drug" "Branded Drug Comp" "Branded Pack" "Clinical Drug" "Clinical Drug Comp"
[6] "CVX" "Ingredient" "Quant Branded Drug" "Quant Clinical Drug"getConceptClassId(cdm,
standardConcept = "Standard",
domain = "Condition")[1] "Clinical Finding"Relationship ID
What relationships do we have between standard concepts?
getRelationshipId(cdm_mock,
standardConcept1 = c("standard"),
standardConcept2 = c("standard"),
domains1 = "condition",
domains2 = "condition")[1] "Due to of"What relationships do we have between non-standard to standard concepts?
getRelationshipId(cdm_mock,
standardConcept1 = c("standard"),
standardConcept2 = c("non-standard"),
domains1 = "condition",
domains2 = "condition")[1] "Mapped from"Drug dose forms
getDoseForm(cdm_mock)[1] "Injectable" "Injection" Vocabulary based codelists using CodelistGenerator
Vocabulary-based codelists using CodelistGenerator
We can use drug hierarchies and relationships to create vocabulary-based codelists.
Drug ingredients
ingredients <- getDrugIngredientCodes(cdm = cdm)
ingredients
- 10318_tacrine (2 codes)
- 10582_levothyroxine (2 codes)
- 11170_verapamil (2 codes)
- 11248_vitamin_b_12 (2 codes)
- 11289_warfarin (2 codes)
- 11636_drospirenone (2 codes)
along with 85 more codelistsingredients$warfarinNULL# Source: SQL [?? x 10]
# Database: DuckDB v1.1.3 [eburn@Windows 10 x64:R 4.4.0/C:\Users\eburn\AppData\Local\Temp\RtmpE1T2Vn\file5a48daf4bd9.duckdb]
concept_id concept_name domain_id vocabulary_id concept_class_id standard_concept concept_code valid_start_date valid_end_date
<int> <chr> <chr> <chr> <chr> <chr> <chr> <date> <date>
1 1310149 Warfarin Drug RxNorm Ingredient S 11289 1970-01-01 2099-12-31
2 40163554 Warfarin Sodi… Drug RxNorm Clinical Drug S 855332 2009-08-02 2099-12-31
# ℹ 1 more variable: invalid_reason <chr>ATC classifications
atc <- getATCCodes(cdm = cdm_mock)
atc
- 1234_alimentary_tract_and_metabolism (2 codes)atc$alimentary_tract_and_metabolismNULLICD10 chapters
icd <- getICD10StandardCodes(cdm = cdm_mock)
icd
- arthropathies (3 codes)
- diseases_of_the_musculoskeletal_system_and_connective_tissue (3 codes)icd$arthropathies[1] 3 4 5Systematic search using CodelistGenerator
Systematic search using CodelistGenerator
CodelistGenerator is used to create a candidate set of codes for helping to define patient cohorts in data mapped to the OMOP common data model.
A little like the process for a systematic review, the idea is that for a specified search strategy, CodelistGenerator will identify a set of concepts that may be relevant, with these then being screened to remove any irrelevant codes.
Codes for asthma
asthma_codes <- getCandidateCodes(cdm=cdm,
keywords= "asthma",
domains = "Condition")
asthma_codes %>% glimpse()Rows: 2
Columns: 6
$ concept_id <int> 4051466, 317009
$ found_from <chr> "From initial search", "From initial search"
$ concept_name <chr> "Childhood asthma", "Asthma"
$ domain_id <chr> "Condition", "Condition"
$ vocabulary_id <chr> "SNOMED", "SNOMED"
$ standard_concept <chr> "S", "S"asthma_cs <- omopgenerics::newCodelist(list("asthma" = asthma_codes$concept_id))
asthma_cs
- asthma (2 codes)Codelist diagnostics
Code counts
asthma_code_use <- summariseCodeUse(asthma_cs,
byYear = TRUE,
bySex = TRUE,
ageGroup = list(c(0,17),
c(18,65),
c(66, 150)),
cdm=cdm) |>
omopgenerics::suppress(minCellCount = 5)
tableCodeUse(asthma_code_use |>
filter(strata_name == "overall"))
Database name
|
|||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
Synthea
|
|||||||||||
| Codelist name | Year | Sex | Age group | Standard concept name | Standard concept ID | Source concept name | Source concept ID | Source concept value | Domain ID |
Estimate name
|
|
| Record count | Person count | ||||||||||
| asthma | overall | overall | overall | overall | - | NA | NA | NA | NA | 101 | 101 |
| Childhood asthma | 4051466 | Childhood asthma | 4051466 | 233678006 | condition | 96 | 96 | ||||
| Asthma | 317009 | Asthma | 317009 | 195967001 | condition | 5 | 5 | ||||
Code counts
tableCodeUse(asthma_code_use |>
filter(strata_name == "year",
strata_level %in% c("2004", "2005", "2006")))
Database name
|
|||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
Synthea
|
|||||||||||
| Codelist name | Year | Sex | Age group | Standard concept name | Standard concept ID | Source concept name | Source concept ID | Source concept value | Domain ID |
Estimate name
|
|
| Record count | Person count | ||||||||||
| asthma | 2004 | overall | overall | overall | - | NA | NA | NA | NA | <5 | <5 |
| 2006 | overall | overall | overall | - | NA | NA | NA | NA | <5 | <5 | |
| Asthma | 317009 | Asthma | 317009 | 195967001 | condition | <5 | <5 | ||||
| 2004 | overall | overall | Asthma | 317009 | Asthma | 317009 | 195967001 | condition | <5 | <5 | |
Code counts
tableCodeUse(asthma_code_use |>
filter(strata_name == "age_group"))
Database name
|
|||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
Synthea
|
|||||||||||
| Codelist name | Year | Sex | Age group | Standard concept name | Standard concept ID | Source concept name | Source concept ID | Source concept value | Domain ID |
Estimate name
|
|
| Record count | Person count | ||||||||||
| asthma | overall | overall | 0 to 17 | overall | - | NA | NA | NA | NA | 96 | 96 |
| 18 to 65 | overall | - | NA | NA | NA | NA | 5 | 5 | |||
| 0 to 17 | Childhood asthma | 4051466 | Childhood asthma | 4051466 | 233678006 | condition | 96 | 96 | |||
| 18 to 65 | Asthma | 317009 | Asthma | 317009 | 195967001 | condition | 5 | 5 | |||